How Large Language Models Work, in Plain English
The chatbots answering your questions are prediction engines trained on text. Here is what they actually do, and where they fall short.
Ask a chatbot a question and it answers in fluent sentences, often within a second. It can feel like talking to something that understands you. Underneath, though, a large language model is doing something narrower and stranger: predicting the next chunk of text, over and over, until a full reply has formed.
That single idea explains most of what these systems get right, and a good deal of what they get wrong. Here is how it works without the jargon.
Everything starts with tokens
A language model does not read words the way people do. Text is first broken into tokens, which are common sequences of characters. A token might be a whole short word, a word fragment, or a piece of punctuation. The sentence you are reading is, to the model, a list of these tokens converted into numbers.
Working in tokens lets a model handle any text, including words it has never seen, by assembling them from smaller familiar pieces. It also means the model’s sense of language is statistical from the very first step. It is manipulating numbers that stand in for fragments of text, not looking up definitions.
Training is prediction at enormous scale
The core of training is simple to state. The model is shown a passage of text with the next token hidden, and it guesses what comes next. When it guesses wrong, its internal settings are nudged slightly so it would do better next time. Repeat this across a vast amount of text and trillions of small adjustments, and the model gradually captures the patterns of how language is used.
Those internal settings are called parameters, and modern models have many billions of them. No human writes these values. They emerge from the training process. Along the way the model picks up grammar, common facts, writing styles, and the rough shape of how ideas connect, simply because reproducing text accurately requires all of that.
A second stage usually follows. Human reviewers rate sample answers, and the model is tuned to favor responses people find helpful, accurate, and safe. This step, often built on reinforcement learning, is a large part of why a research model becomes a usable assistant.
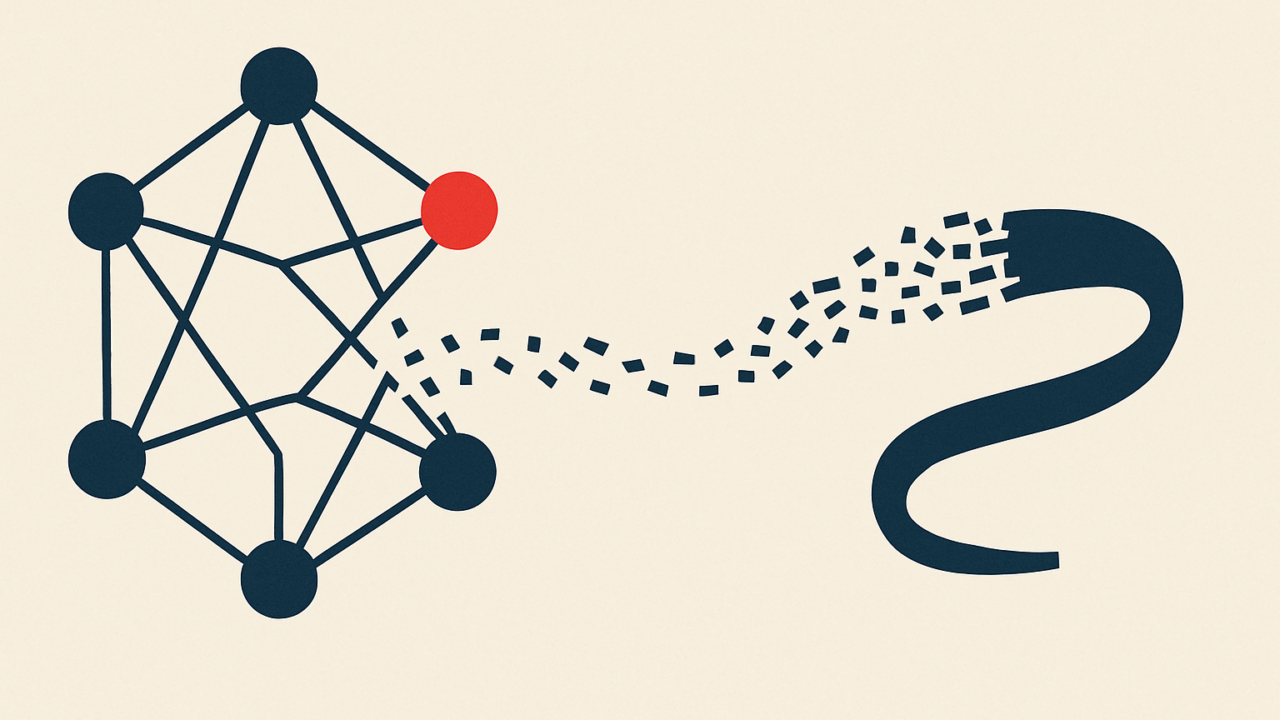
The transformer and the trick of attention
Almost every modern language model is built on an architecture called the transformer, introduced by Google researchers in 2017. Its key idea is a mechanism called attention, which lets the model weigh how much each token in the input should influence each other token.
Attention is what allows the model to keep track of context. When it reaches the end of a long sentence, attention helps it connect a pronoun back to the right noun, or a verb back to the right subject, even when they are far apart. This is the breakthrough that made today’s fluency possible.
A language model does not retrieve a stored answer. It generates one token at a time, each choice shaped by everything written so far.
Because generation is sequential, the text builds on itself. Once the model commits to an opening, that opening shapes what follows, which is why the same question can yield differently worded answers on different tries.
Why fluent does not mean factual
The most important thing to understand is what the model is optimizing for. It is trained to produce text that is likely and well-formed, not text that is verified as true. Usually the likely continuation is also the correct one, because accurate text is well represented in the training data. But not always.
When a model states something false in a confident tone, that is often called a hallucination. It is not lying, because it has no concept of truth to violate. It has produced a fluent, plausible string of tokens that happens to be wrong. This is a known and documented limitation, not a bug to be patched away.
A few practical consequences follow for anyone using these tools:
- Treat specific facts, figures, names, dates, and quotations as claims to verify, not as settled answers.
- Expect the model’s knowledge to have a cutoff. Unless it is connected to live search, it cannot know recent events.
- Remember that a confident tone carries no information about accuracy. The wording sounds equally sure whether it is right or wrong.
None of this makes language models useless. They are genuinely good at drafting, summarizing, explaining concepts, restructuring text, and brainstorming, tasks where fluency and pattern-matching are exactly what you want. The skill is in matching the tool to the job: lean on it for language, and keep a human in the loop for facts.
Marcus Reed
Marcus Reed reports on technology for Tilias News — artificial intelligence, consumer products, platforms and the rules that govern them. He focuses on what new tools actually change for ordinary people.